
Applying Kafka Streams to the Purchase Transaction Flow
by
Maybe you know a bit about Kafka and/or Kafka Streams (and maybe you don’t and are burning up with anticipation…). Rather than tell you about how Kafka Streams works and what it does, I would like to jump straight into a practical example of how you can apply Kafka Streams directly to the purchase flow transaction – so you can see Kafka Streams in Action for yourself!
NOTE: (Save 37% off Kafka Streams in Action with code streamkafka)
Let’s start by building a processing graph with a Kafka Streams program. Here’s the requirements graph for the project:
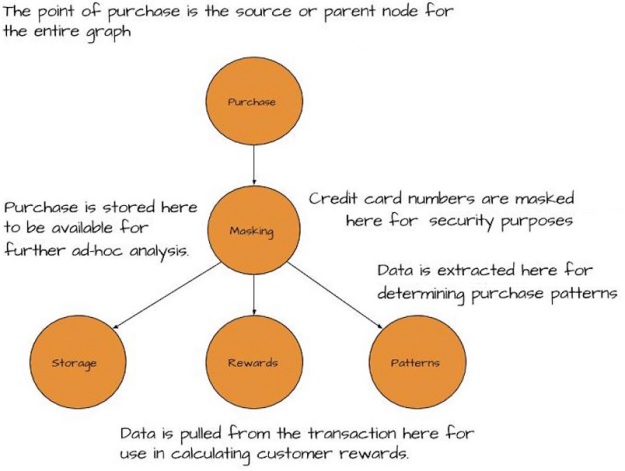
Figure 1 Here’s the view of our business requirements cast in a graph. Vertexes are processing nodes that handle data and the edges show the flow of data.
Next, we’ll build a Kafka Streams program concurrent to this graph. It’s a relatively high-level approach, and some details have been left out to keep the article from being overwhelming.
Once our Kafka Streams program starts to consume records, we convert the raw messages into objects. Specifically shown here are pieces of information for Transaction that will make up the transaction object:
-
Your ZMart customer id (you scanned your member card).
-
The total dollar amount spent.
-
The item(s) you purchased.
-
The zip code of the store where the purchase took place.
-
The date and time of the transaction.
-
Your debit/credit card number.
Defining the Source
The first step in any Kafka Streams program is to establish a source for the stream. The source could be any of the following:
-
A single topic
-
Multiple topics in a comma-separated list
-
A regex that can match one or more topics
In this case, we will use the “transaction” single topic. A Kafka Streams program runs one or more StreamThread (the number of Stream threads are user-defined) instances. Each StreamThread has an embedded Consumer and Producer that handles reading from, and writing to, Kafka. In addition to specifying source topic(s), you also provide Serdes for the keys and values. A Serdes instance contains the serializer and deserializer needed to convert objects to byte arrays/byte arrays to objects, respectively.
NOTE - What is a Serdes?
Serdes is a class, containing a Serializer/Deserializer pair for a given object.
In this case, we will work with the Purchase object, because it defines methods that aid in the processing work. You will provide key serdes, value serdes and source topic(s) to a KstreamBuilder, which returns a KStream instance. You will use this KStream object throughout the rest of the program. The value deserializer automatically converts the incoming byte arrays into objects, as Purchase messages continue to flow into the stream.
It’s important to note that, to Kafka itself, the Kafka Streams program appears as any other combination of consumers and producers. There could be any other number of applications reading from the same topic in conjunction with your streaming program.

Figure 2 Here’s the source node, but instead of using the vague term “source”, we’ll call this what it is - a Kafka topic.
The First Processor - Masking Credit Card Numbers
Now you’ve defined your source, and we can start creating processors that’ll do the work on the data. The first goal is to mask the credit card numbers recorded in the incoming purchase records. The first processor is used to convert credit card numbers from 1234-5678-9123-2233 to xxxx-xxxx-xxxx-2233. The Stream.mapValues method performs the masking. The KStream.mapValues method returns a new KStream instance that changes the values, as specified by the given ValueMapper, as records flow through the stream. This particular KStream instance is the parent processor for any other processors you define. Our new parent processor provides the masked credit-card numbers to any downstream processors with Purchase objects.
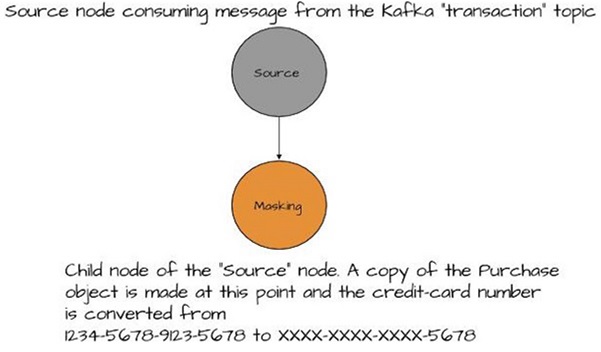
Figure 3 This is the masking processor, and it’s a child of the main source node. It receives all the raw sales transactions and emits new records with the credit card number masked. All other processors receive their records from this processor.
CREATING PROCESSOR TOPOLOGIES
I’d like to quickly say a few words on creating processor topologies, before we continue down transaction lane. Each time you create a new KStream instance by using a transformation method, you’re building a new processor. That new processor is connected to the other processors that have already been created. By composing processors, we can use Kafka Streams to elegantly create complex data flows.
It’s important to note that calling a method that returns a new KStreams instance doesn’t cause the original to stop consuming messages. When using a transforming method, a new processor is created and added to the existing processor topology. The updated topology is used as a parameter to create the new KStream instance. The new KStream object starts receiving consumed messages from the point of its creation. It’s likely you’ll build new KStream instances to perform additional transformations, while retaining the original stream to continue consuming incoming messages for an entirely different purpose. You’ll see an example of this when we define the second and third processors.
It’s possible to have a ValueMapper convert the incoming value to an entirely new type, but in this case, it’ll return an updated copy of the Purchase object. Using a “mapper” to update an object is a pattern seen over and over in KStreams. Each transforming method returns a new instance of a KStream that applies some function to all incoming data at that point.
Now you should have a clear image of how we can build up our processor “pipeline” to transform and output data. Next, we move on to creating the next two processors using the first processor that we built as a parent processor.
The Second Processor - Purchase Patterns
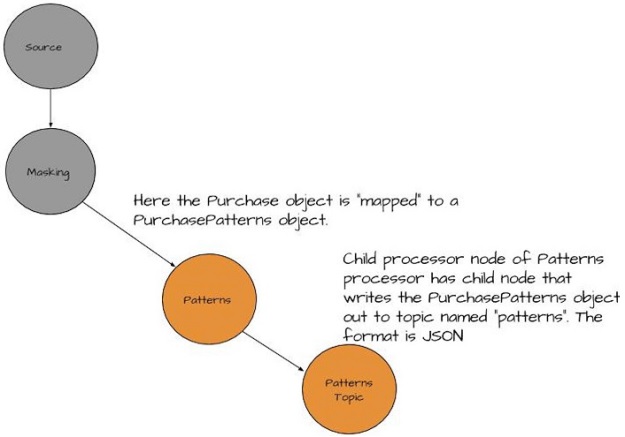
Figure 4 Here’s the purchase patterns processor. It’s responsible for taking Purchase objects and converting them into Purchase Pattern objects, containing the item purchases and the zip code where the transaction took place. We’ve added a new processor that takes records from the patterns processor and writes them out to a Kafka topic.
Next in the list of processors that need to be created is one that captures information to determine purchase patterns in different regions of the country. To do this, we add a child processing node to the first processor/KStream we created. Let’s call this first KStream instance purchaseKStream. The purchaseKStream produces Purchase objects with the credit card number masked.
The purchase patterns processor receives a Purchase object from its parent node and “maps” the object of a new type, a PurchasePattern object. The mapping process extracts the actual item purchased (toothpaste) and the zip code it was bought in, and uses that information to create the PurchasePattern object. Next, the purchase patterns processor adds a child processor node that receives the newly-mapped object and writes it out to a Kafka topic named “patterns”. The object is converted to some form of transferable data PurchasePattern when written to the topic. Other applications can consume this information and use it to determine inventory levels, as well as purchasing trends in a given area.
The Third Processor - Customer Rewards
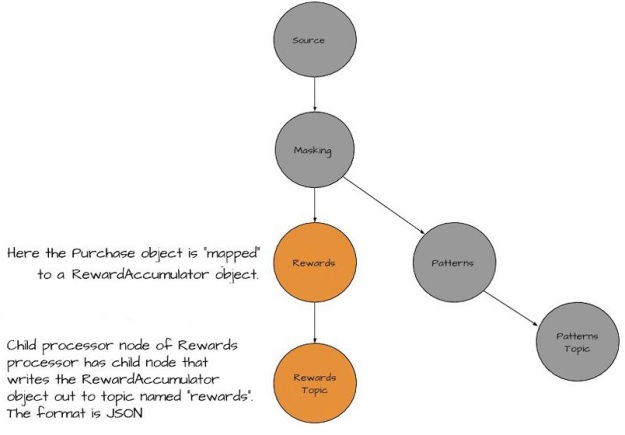
Figure 5 Here’s the customer rewards processor responsible for transforming Purchase objects into a RewardAccumulator object containing the customer id, date, and total dollar amount of the transaction. We’ve also added another child processor here to write the Rewards objects to another Kafka topic.
The third processor created extracts the required information for the customer rewards program. This processor is also a child node of the purchaseKStream processor. The rewards processor, similar to the purchase patterns processor, receives the Purchase object and “maps” it into a RewardAccumulator object.
The reward processor also adds a child processing node to write the RewardAccumulator object out to a Kafka topic called “rewards”. It is from consuming records from the “rewards” topic that another application would determine any rewards for Zmart customers.
Fourth Processor - Writing Purchase Records
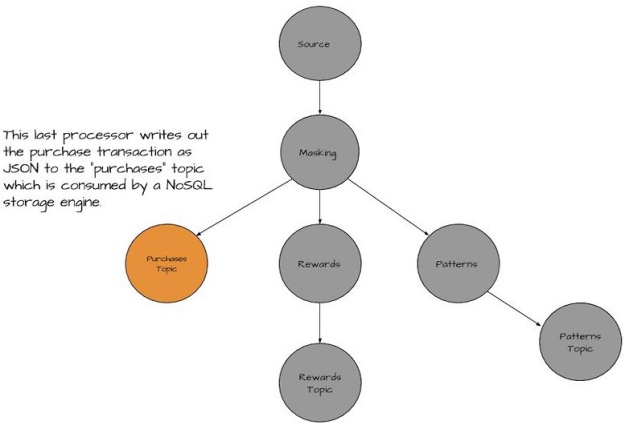
Figure 6 This is the final processor in the topology. This processor is responsible for writing out the entire Purchase object to another Kafka topic. The consumer for this topic stores the results in a NoSql store, such as MongoDB
The last processor and third child node of the masking processor node writes the purchase record out to a topic “purchases”. The purchases topic is used to feed a NoSQL storage application that consumes the records as they come in. These records are used for ad-hoc analysis later. This record contains all the information from the purchase example above.
We’ve taken the first processor that masked the credit card number and we used it to feed three other processors; two that further refined or transformed the data, and one that wrote the masked results out to a topic for further use by other consumers. You can see how using Kafka Streams allows us to build a powerful processing “graph” of connected nodes to perform data integration tasks in a stream processing manner.
That’s all for this article. For more, download the free first chapter of Kafka Streams in Action, and don’t forget to save 37% with code streamkafka at manning.com.
Subscribe via RSS