
Machine Learning with Kafka Streams
by
 The last two posts on Kafka Streams (Kafka Processor API, KStreams DSL) introduced kafka streams and described how to get started using the API. This post will demonstrate a use case that prior to the development of kafka streams, would have required using a separate cluster running another framework. We are going to take live a stream of data from twitter and perform language analysis to identify tweets in English, French and Spanish. The library we are going to do this with is LingPipe. Here’s a description of Ling-Pipe directly from the website:
The last two posts on Kafka Streams (Kafka Processor API, KStreams DSL) introduced kafka streams and described how to get started using the API. This post will demonstrate a use case that prior to the development of kafka streams, would have required using a separate cluster running another framework. We are going to take live a stream of data from twitter and perform language analysis to identify tweets in English, French and Spanish. The library we are going to do this with is LingPipe. Here’s a description of Ling-Pipe directly from the website:
LingPipe is tool kit for processing text using computational linguistics. LingPipe is used to do tasks like:
- Find the names of people, organizations or locations in news
- Automatically classify Twitter search results into categories
- Suggest correct spellings of queries
The Hosebird Client from Twitter’s Streaming API will be used to create the stream of data that will serve as messages sent to kafka.
Before diving into the KStreams program, a description of setting up Hosebird and how the classification will be performed is in order.
Setting Up The Hosebird Client
In order to use Hosebird an appication needs to be registered with Twitter and access tokens generated.
Application Registration, API Key and Access Key Generation
The first step is application registration. Once the application is created. copy the consumer key (API key) and the consumer secret from the screen and save them in a properties file. Next click on Create my Access Token to generate the tokens required to give your twitter account access to the new application. Full instructions on this process can be found here.
Coding the Hosebird Client
The code for running the Hosebird client is really a matter of providing the generated keys for authentication, search terms and other basic parameters to the ClientBuilder API:
private Client getTwitterClient(Properties props,
BlockingQueue<String> messageQueue) {
String clientName = props.getProperty("clientName");
String consumerKey = props.getProperty("consumerKey");
String consumerSecret = props.getProperty("consumerSecret");
String token = props.getProperty("token");
String tokenSecret = props.getProperty("tokenSecret");
List<String> searchTerms = Arrays.asList(props.getProperty("searchTerms").split(","));
Authentication authentication = new OAuth1(consumerKey,consumerSecret,token,tokenSecret);
Hosts hosebirdHosts = new HttpHosts(Constants.STREAM_HOST);
StatusesFilterEndpoint hosebirdEndpoint = new StatusesFilterEndpoint();
hosebirdEndpoint.trackTerms(searchTerms);
ClientBuilder clientBuilder = new ClientBuilder();
clientBuilder.name(clientName)
.hosts(hosebirdHosts)
.authentication(authentication)
.endpoint(hosebirdEndpoint)
.processor(new StringDelimitedProcessor(messageQueue));
return clientBuilder.build();
}
Publishing Tweets to Kafka
The next step is to start streaming the twitter data and publishing individual tweets to a KafkaProducer. The search terms used are Real Madrid,#realmadrid,@lemondefr,Le Monde. These terms proved to have a nice mix of all three of the target languages.
//Details left out for clarity
try {
BlockingQueue<String> twitterStreamQueue = new LinkedBlockingQueue<>();
streamSource = getTwitterClient(props, twitterStreamQueue);
producer = getKafkaProducer();
int maxMessages = 500000;
int counter = 0;
streamSource.connect();
while (counter++ < maxMessages) {
String twitterMessage = null;
try {
twitterMessage = twitterStreamQueue.take();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
ProducerRecord<String, String> message = new ProducerRecord<>("twitterData", twitterMessage);
producer.send(message);
}
} finally {
stop();
}
Nothing to fancy here, jut pull a tweet from the queue, create a ProducerRecord, and then send the message to kafka. Now the data stream is up and running. Up next is a look at how the data classification is done.
Classifying The Data
Describing how language classification works is beyond the scope of this post. Just a brief description of the classes used and the practical application to our problem is covered. The LingPipe library is being used to classify the data. Specifically, the DynamicLMClassifier class is what will be trained and used to classify the tweet data. The DynamicLMClassifier is a language model classifier that uses categorized (annotated) character sequences for training and classification.
Training Data
The data used to train the classifier is a csv file consisting of the label, which is one of our target languages (English, French or Spanish) followed by text in the target language . The training data looks like this:
spanish#se ven cuatro hoteles que pueden citarse entre los más lindos de París.
french#Huit cents. Mais je m'étonne si monsieur à jamais vu la couleur deleur argent.
english#The house stood on a slight rise just on the edge of the village. It stood on
A ‘#’ is used as the delimiter as several portions of the training text contains commas. In total there are roughly 50 lines for each language, not extensive, but enough for our purposes.
Training The Classifier
The code for the training the classifier is surprisingly simple:
public class Classifier {
//Details left out for clarity
public void train(File trainingData) throws IOException {
Set<String> categorySet = new HashSet<>();
List<String[]> annotatedData = new ArrayList<>();
fillCategoriesAndAnnotatedData(trainingData, categorySet, annotatedData);
trainClassifier(categorySet, annotatedData);
}
private void trainClassifier(Set<String> categorySet, List<String[]> annotatedData){
String[] categories = categorySet.toArray(new String[0]);
classifier = DynamicLMClassifier.createNGramBoundary(categories,maxCharNGram);
for (String[] row: annotatedData) {
String actualClassification = row[0];
String text = row[1];
Classification classification = new Classification(actualClassification);
Classified<CharSequence> classified = new Classified<>(text,classification);
classifier.handle(classified);
}
}
public String classify(String text){
return classifier.classify(text.trim()).bestCategory().toLowerCase();
}
}
The train method populates the categorySet (languages) and the annotatedData list which contains both the category(language) and the language text. The heart of the program is the trainClassifier method which iterates over the annotated data, creating a Classification object from the language label, a Classified object from the data and the classification. The Classified instance is passed to the classifier via the handle method which provides a training instance for the given string. The training code shown here was inspired heavily from the LingPipe Cookbook. Now that all the setup has been covered, it’s time to move on to using kafka-streams to process the twitter data.
Using Kafka Stream to Analyze The Data
Now it’s time to cover the main point of this post, running a kafka-stream application to perform language classification on incoming messages. Then the language classification is used to split the original stream into 3 new streams of messages.
public static void run() {
//...Details left out for clarity
Classifier classifier = new Classifier();
classifier.train(new File("src/main/resources/kafkaStreamsTwitterTrainingData_clean.csv"));
KeyValueMapper<String, Tweet, String> languageToKey = (k, v) ->
StringUtils.isNotBlank(v.getText()) ? classifier.classify(v.getText()):"unknown";
Predicate<String, Tweet> isEnglish = (k, v) -> k.equals("english");
Predicate<String, Tweet> isFrench = (k, v) -> k.equals("french");
Predicate<String, Tweet> isSpanish = (k, v) -> k.equals("spanish");
KStream<String, Tweet> tweetKStream = kStreamBuilder.stream(Serdes.String(), tweetSerde, "twitterData");
KStream<String, Tweet>[] filteredStreams = tweetKStream.selectKey(languageToKey).branch(isEnglish, isFrench, isSpanish);
filteredStreams[0].to(Serdes.String(), tweetSerde, "english");
filteredStreams[1].to(Serdes.String(), tweetSerde, "french");
filteredStreams[2].to(Serdes.String(), tweetSerde, "spanish");
//...Details left out for clarity
}
While this code is simple, a description of what’s going is in order:
- On line 4 the
Classifierobject (just a wrapper around the Ling-Pipe classes) is created. On line 5 the classifier is trained with the given data file described previously. - On line 7 a
KeyValueMapperinstance is created. While this is just one line of code, it is the key of the entire program as this is where the classification occurs. The text of the tweet is classified and the result is used as the key for theKeyValuepair. - Lines 10-12 are the predicates used to filter the incoming stream.
- Line 16 is where all the work comes together. The
tweetKStreamuses theKStream.selectKeymethod to create a new key, which is the language classification of the value. Then theKStream.branchmethod is called using the three predicates created previously. TheKStream.branchmethod takes N number predicates and returns an Array of containing N KStream instances. Each KStream in the Array produces KeyValue pairs that evaluate to true for the respective predicate from thebranchmethod. AKeyValueobject will be associated with the first prediate that it matches on.
Results
Here is a screen-shot of the results. This is a tmux session with the top window is reading from the Spanish topic, the middle is French and the bottom is English:
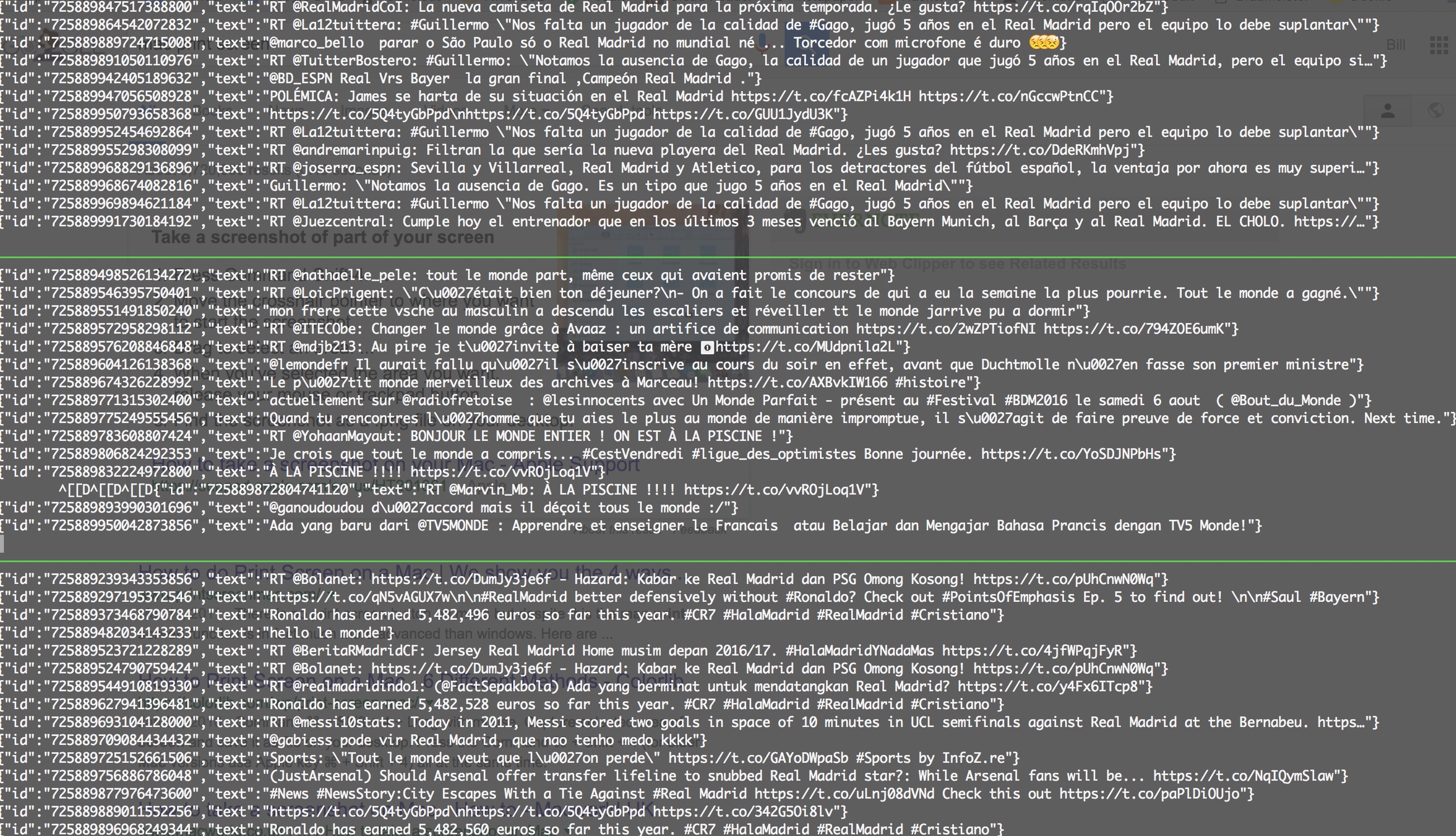
While the results are not 100% accurate, for the amount of training done it’s not all that bad. Notice that the Real Madrid results were concentrated the most in the English and Spanish topics, while the Le Monde twitter results showed up exactly where expected.
Conclusion
While langage classification is not new, and can be done in a variety of ways, hopefully from this little example we can see how Kafka-Streams can be used to perform analysis/transformation on incoming data that previously required using a separate framework.
Resources
- Stream Processing Made Simple a blog post from Confluent describing Kafak Streams
- Kafka Streams Documentation
- Kafka Streams Developer Guide
- Confluent
- Source code and instructions to run examples for this post. Note that all of the streaming examples use simulated streams and can run indefinitely.
- LingPipe
Subscribe via RSS