
Relationship Between Streams and Tables
by
In this blog post, we’re going to look deeper into adding state. Along the way, we’ll get introduced to new abstraction, the KTable, after which we will move further to discuss how event streams and database tables relate to one another in Kafka’s Streaming API.
NOTE: (Save 37% off Kafka Streams in Action with code streamkafka)
When covering the KStream API, we’re talking about individual events or an event stream. When “Jane Doe” makes a purchase, we consider the purchase as an individual event. We don’t keep track of how often or how many purchases Jane has carried out before.
If you think about the purchase event stream concerning a database, it can be considered a series of inserts. Because each record is new and unrelated to any other records, we continually insert records into a table.
Now let’s add some context by adding a key to each purchase event. Going back to Jane Doe, we now have a series of updated purchase events. Because we’re using a primary key (customer-id) each purchase is now an update to any previous purchase Jane made. Treating an event stream with keys as inserts and events with keys as updates is what we use to define the relationship between streams and tables.
The Relationship between Streams and Tables
A stream as an infinite sequence of events, but stating “infinite sequence of events” is generic; let’s narrow it down with a specific example.
A Record Stream
To demonstrate a record or event stream, a series of stock price quotes for example, we can use the image below:
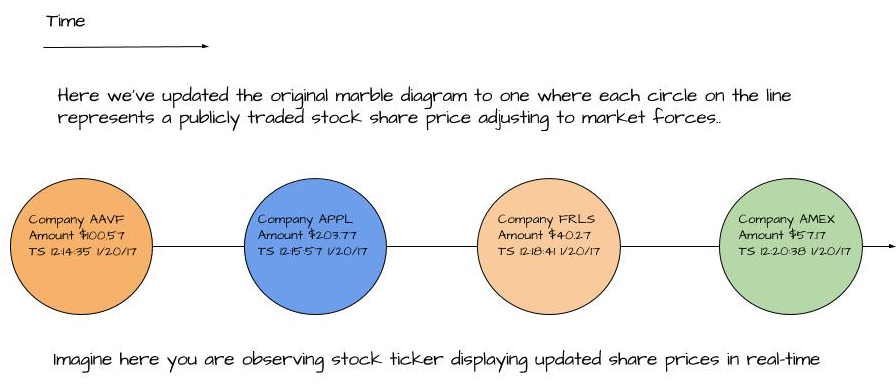
We can see from this picture that each stock price is a discrete event and they aren’t related to each other. Even if the same company accounts for many price quotes, we’re only looking at them one at a time.
This view of events is how the KStream works. The KStream is a stream of records. We can show how this concept ties into database tables. In the next image, we present a simple stock quote table:
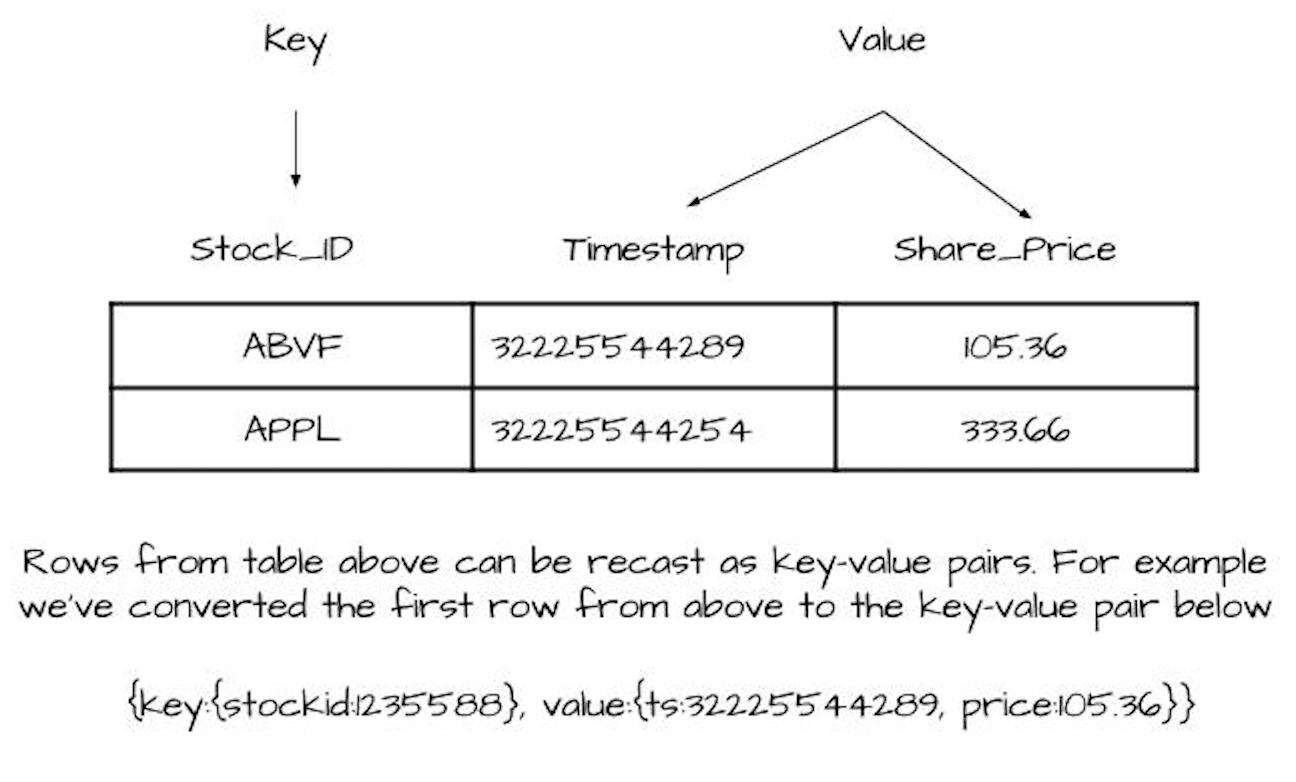
This simple database table represents stock prices for companies. There’s a key column, and other columns contain the values. It’s fair to say we have a key-value pair if we lump the other columns into a “value” container.
Now let’s take another look at the record stream. Because each record stands on its own, the stream represents inserts into a table. In the following image, we’ve combined the two concepts to illustrate this point:
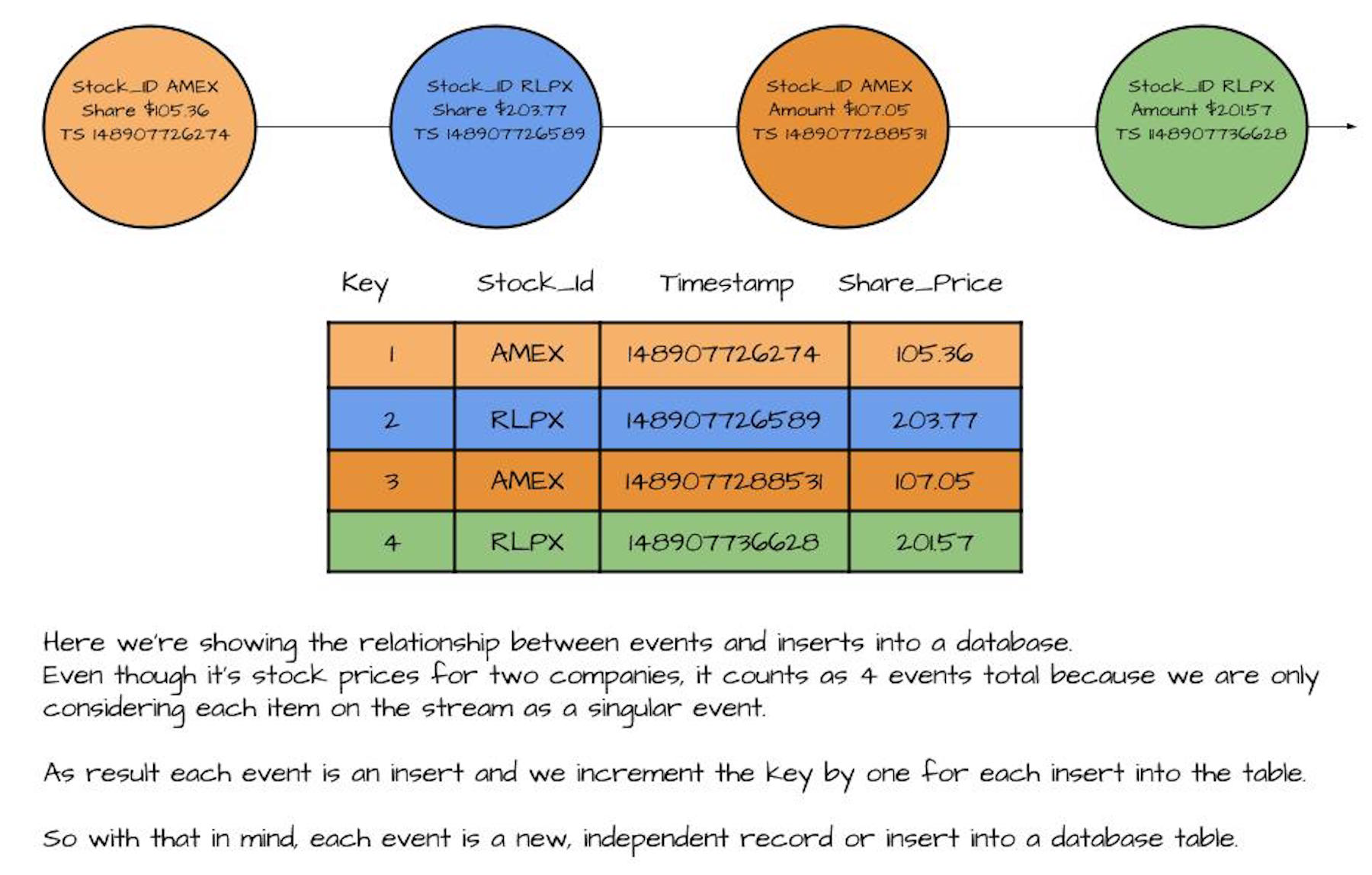
Here we see how a stream of individual events compared to inserts in a database table. We can flip this around and look at how we could stream each row of the table.
What’s important here is that we can view a stream of events in the same light as inserts into a table, which helps give us a deeper understanding of using streams for working with events.
The next step in our comparison of streams to tables is to consider the case when several flows of events have something to do with each other.
Updates to Records or the Change Log
Let’s take the same stream of customer transactions, but now we want to track activity over time. If we alter the key to the customer id, instead of a stream of records we have a stream of updates. In this case, no record stands alone, and we can consider this a stream of updates or a change log. The image below demonstrates this concept:
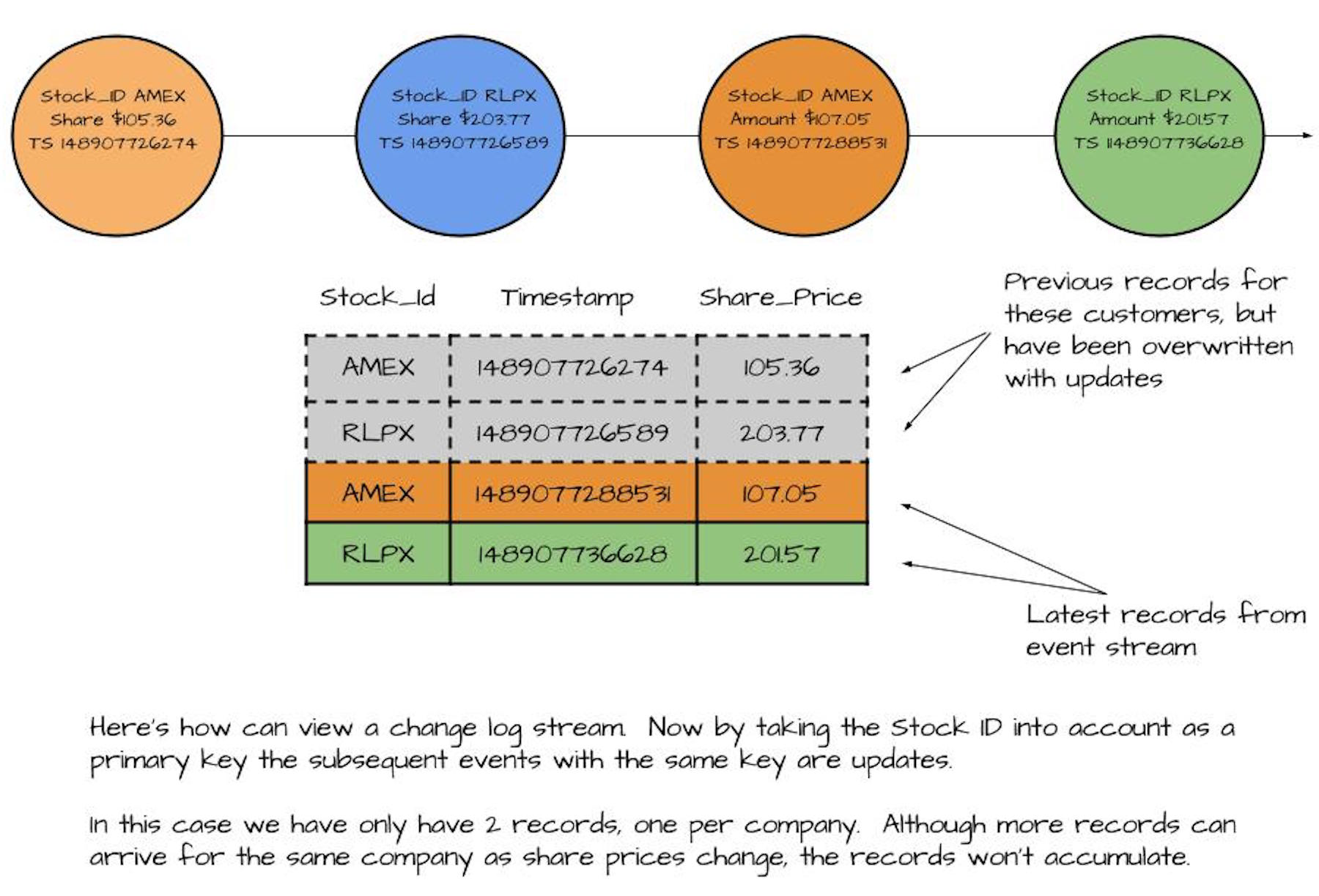
No record pictured above stands on its own. With a record stream, we would have a total count of four events. In the case of updates or a change log, we only have one. Each incoming record overwrites the previous one with the same key.
Here we can see the relationship between a stream of updates and a database table. Both the log and change log represent incoming records appended to the end of a file. In a log, we need to see all the records. But with a change log, we only want to keep the latest record for any given key.
Log vs. Change Log
With both the log and change log, as records come in they are always appended at the end of the file. The distinction between the two is in a log where you want to read all records, but in a change log, you only want the latest record for each key.
Now we need a way to trim down the log as we maintain those latest arriving records (per key). The good news is that we have an approach that works – log compaction. Let’s take another look at the image for review:
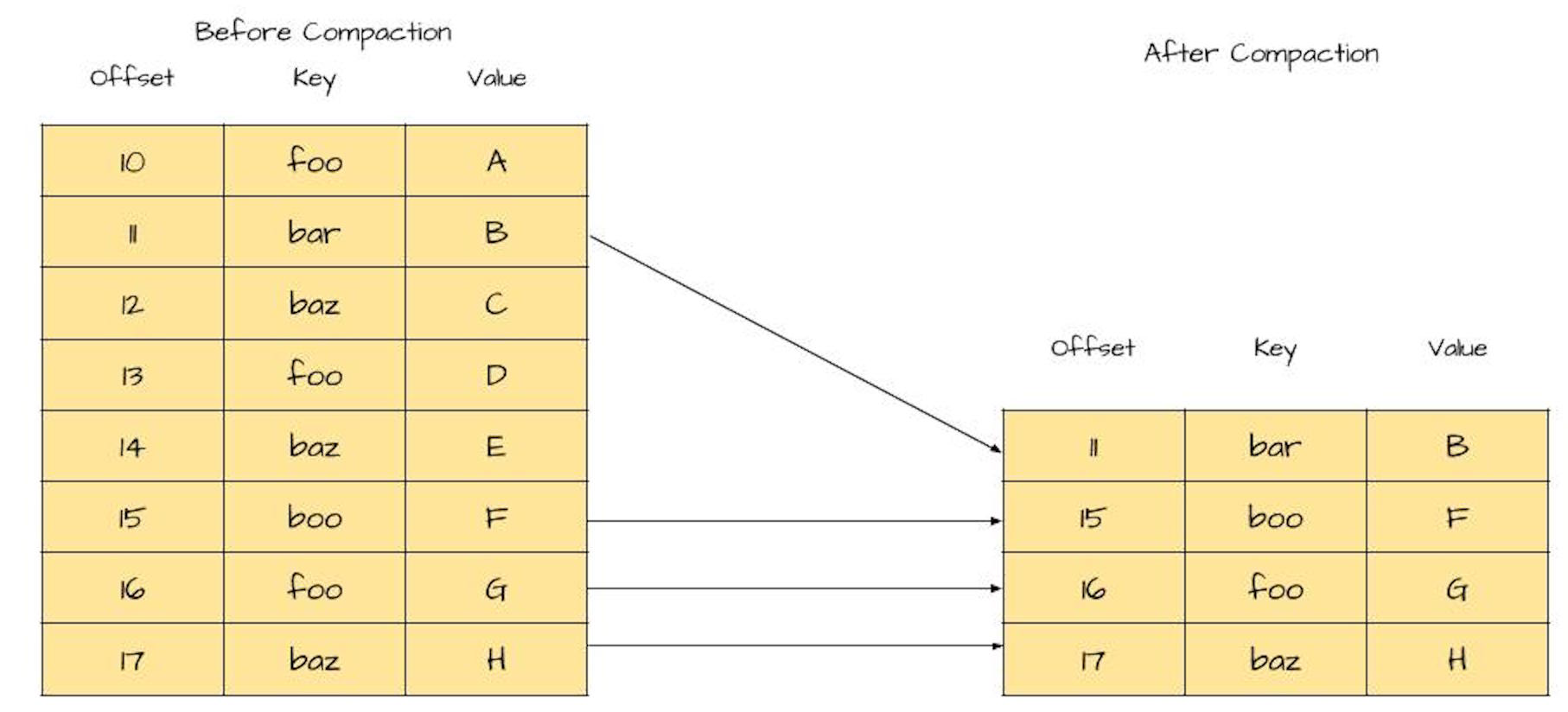
On the left is a log before compaction. You’ll notice duplicate keys with different values, which are updates. On the right is the log after compaction. Notice we keep the latest value for each key, but the log is smaller in size.
We can see the impact of the compacted log in this image. Because we only care about the latest values, we can remove older key-value pairs (This section derived information from Jay Kreps in https://www.confluent.io/blog/introducing-kafka-streams-streamprocessing-made-simple/).
We’re already familiar with record or event streams from working with KStreams. For a change log or stream of updates, Kafka Streams provides the KTable. Now that we’ve established the relationship between streams and tables, our next step is to compare an event stream to an update stream. We’ll make this comparison by watching a KStream and KTable in action side by side.
Event Streams vs Update Streams
In this section, we’ll show event and update streams by comparing the KStream to the KTable. We’ll do this by running a simple stock ticker application. The stock ticker application writes the current share price for three (fictitious!) companies. We’ll produce three iterations of stock quotes for a total of nine records.
A KStream and KTable instance reads the records and writes them to the console via the print method. The following image shows the results of running the application:

As you can see from the results, the KStream printed all nine records out. We expect the KStream to behave this way as it views each record as an individual event. In contrast, the KTable only printed three records. From what we learned above, though, this is how we’d expect the KTable to perform.
The Need for Primary Keys
The example in the previous section demonstrated how a KTable works with updates. There was an implicit assumption that I’ll make explicit here. When working with a KTable, your records must have populated keys in the key-value pairs. Having a key is essential for the KTable to work. As you can’t update a record in a database table without having the key, the same rule applies here as well.
From the KTable point of view, it didn’t receive nine individual records. The KTable received three original records and updates to those records twice. The KTable only printed the last round of updates. Notice the KTable records are the same as the last three records published by the KStream.
Here’s our program printing stock ticker results to the console:
KTable<String, StockTickerData> stockTickerTable = kStreamBuilder.table(STOCK_TICKER_TABLE_TOPIC, "ticker-store");
KStream<String, StockTickerData> stockTickerStream =kStreamBuilder.stream(STOCK_TICKER_STREAM_TOPIC);
stockTickerTable.toStream().print( "Stocks-KTable");
stockTickerStream.print( "Stocks-KStream");
Here are the main points of the simple program above
- Creating the KTable instance (line 1)
- Creating the KStream instance (line 3)
- KTable printing results to the console (line 5)
- KStream printing results to the console (line 6)
Serdes Configuration
I should point out that in creating the KTable and KStream we didn’t specify any Serdes to use. The same is true with both calls to the print method. We were able to do this because we registered our default Serdes in the configuration like this:
props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG,Serdes.String().getClass().getName());
props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG,StreamsSerdes.StockTickerSerde().getClass().getName());
If we used different types then we’d need to provide Serdes in any method reading or writing records.
The takeaway here is that records in a stream with the same key are updates to events, not new events by themselves. A stream of updates is the main concept behind working with the KTable.
That’s all for this article. For more, download the free first chapter of Kafka Streams in Action.
Subscribe via RSS